The Complete Guide to Web Scraping
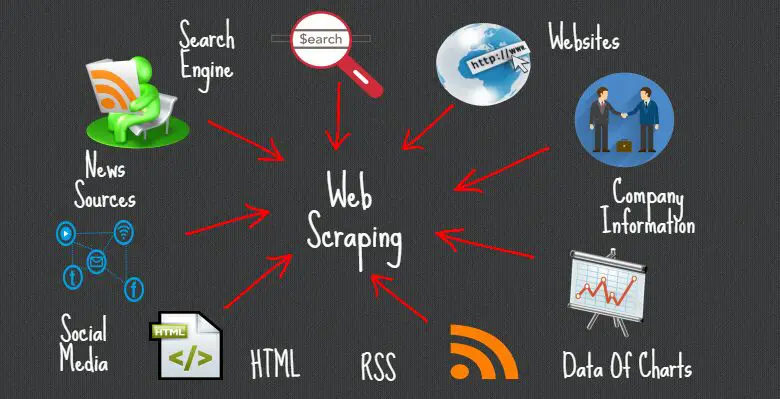
Going around websites, manually copying and pasting information into spreadsheets and notepads for later analysis, is sometimes the only way to gather information. But this process can be very monotonous and time-consuming. Thankfully, there is a way to improve this process: and it is automation.
Web scraping is entirely based on automation. It’s a technique that uses bots to do what a human would do when extracting data from websites and organizing it in a structured way. But some web scrapers would often abuse, and use their automation scripts to send armies of bots to gather information, making websites unstable and slow. That is precisely why web scraping is often mitigated and blocked by websites.
In this post, you’ll learn everything about web scraping, its process, how to start, and how to avoid being blocked.

1. What is Web Scraping?
Web scraping which is also known as web data extraction is the process of automatically extracting data from websites. Web scraping uses software (script or bot) to crawl through websites, extracting all unstructured information, and copying it in a structured manner. The information is usually stored in a database or spreadsheet for further analysis.
What are web scraping use cases? Web scraping can be very useful for monitoring price changes, comparing prices, product reviews, extracting price lists, tracking flight prices, watching the competition, collecting real-estate listings, monitoring weather, etc. Web scraping is also used as a component in applications used for web indexing, such as Google’s web crawlers, or SEO crawler software.
Web Scraping vs Data Scraping?
Web scraping belongs to a wider concept known as data scraping. To clarify their difference, the concept of web scraping only refers to web targets, including websites, web services, or web apps. Data Scraping, on the other hand, refers to everything including local servers, machines, devices, and the web.
Web Scraping vs Web Crawling?
The difference between web crawler and web scraper is that crawlers use web spiders (bots) to fetch data on a website, first by going through the website’s ROBOTS.txt. This is a document that points spiders in the right direction. It contains directions like allow, disallow, sitemap, and user-agent. Web scraping on the other hand usually does not consult the ROBOTS.txt, because it attempts to replicate human-like browsing behaviors.
2. Web Scraping Process

The process for web scraping is as follows: Target a Site > Collect Data > Structure Data.
The first step of web scraping is defining the target. Select the website that you want to fetch and extract data from. Web scrapers usually download a target page and its contents (fetch it), and then proceed to extract specific data.
Data Collection

After the target site is selected, use special software developed for web scraping, to perform the data collection. Web scraping tools were originally designed to automatically, read, and interpret web pages as a human eye would, matching the patterns in text. But now, more modern tools can parse HTML and even DOM and extract entire data feeds from web servers.
Structure Data
These web scraping solutions will attempt to automatically identify the structure of data within a page. These tools will also provide scripting functions to extract and transform data, and database interfaces to store all the scraped data. Some web scraping tools can also be used to extract data using the API of a website or service. Some services like weather or public sites provide an API so that users can use web scraping tools to collect data directly from the API.
Web Scraping Tools
The most primitive type of web scraping tool is the manual copy/paste. When you go into a website, explicitly examine data, copy it into the clipboard, and paste it into a text file or spreadsheet, you are web scraping. But as mentioned above, this manual process has been automated. Now, web scraping tools can perform text pattern matching, HTML parsing, DOM parsing, and even machine vision analysis, to help you extract data from the web.
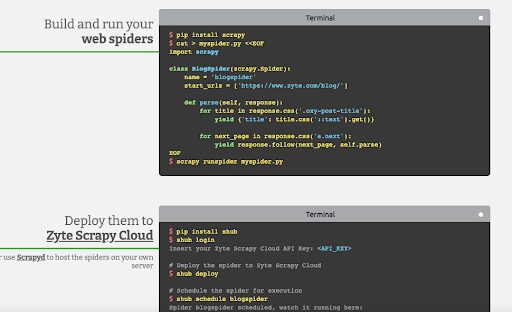
- Dedicated scrappers. One of the most popular examples of a web scraping tool is the free and open-source Scrappy. This software helps you extract data from websites, process it, and store them in a specific format (CSV, XML, or JSON). With Scrappy, you can build and run your web spiders and even scale your spiders via their Zyte Scrappy Cloud.
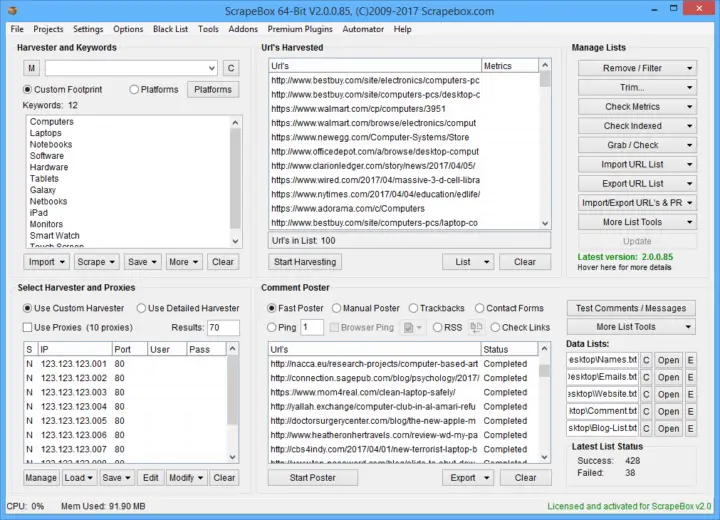
- Specialized Scrappers. There are other kinds of web scraping tools that are more specialized. For example, ScrapeBox, known as the swiss army of SEO, is designed for SEO and marketing. Scrapebox allows you to select a URL (or list of URLs), harvest keywords, use it with proxies (to avoid detection), and even automatically post comments. Scrapebox is a quite comprehensive tool. It scrapes entire lists of URLs, performs special processes like looking for specific keywords, and on top of that, allows you to customize your proxy list.
How and Why is Web Scraping Blocked?
A big percentage of websites attempt to prevent web scraping. They simply disallow bots from crawling their pages. But a big percentage of websites would also put detection mechanisms using WAFs or CDNs. These sites would quickly check your source IP against ban-lists with several IPs that are associated with volumetric traffic or bot-like behavior. If they detect an IP with a bad reputation or identify abnormal behavior they would simply block your traffic.
For example, if you are web scraping a target with a script using your original IP, you will likely be labeled as risky traffic, and your home IP will be banned and sent to intelligence IP systems that spread ban-lists across the word.
How To Start Web Scraping?
To start web scraping, define your target (URL and its data). What type of information are you trying to gather? Is it an SEO analysis? Or maybe tracking price changes?
What do you need? There are two key tools you’ll be needing to start your web scraping campaigns. The web scraping script (or tool) and the proxy server.
a. Get a Web Scraping Tool
If you go for open-source frameworks such as Scrappy, you’ll need some scripting skills, especially in Python, JAVA, or JavaScript. Most of these tools are already automated for web-scraping. Some of these tools can send queries in DOM or JSON. But they also have control over HTTP Requests/Responses.
Other tools such as ScrapeBox or ScreamingFrog are more specialized and come with WebUI and more features. Not all of these tools are free.
b. Get Proxy Servers
Proxy servers are useful to avoid getting your IP blocked and keep source traffic random and fresh. Proxies can help bypass firewalls, WAFs, and CDNs.
For example, a rotating IPv6 proxy provider, such as Rapidseedbox can guarantee a fresh IP for every web scraping session, making web scraping totally undetectable.
Final Words
Web scraping can help you automate the website information extraction process that would otherwise take you days of tedious manual copying and pasting.
When web-scraping, use automation tools but always remember to use them behind a proxy server, like Geonode. As your IP could easily be detected and blocked.
Also, send low volumes of traffic and always use rotation proxies with fresh IPs. And remember to always, web scrape responsibly!